

SST vs LoRA: A Leaner, Smarter Way to Train AI Models
Table of Links
Abstract and 1. Introduction
-
Related Work
-
Low Rank Adaptation
3.1 LoRA and 3.2 Limitation of LoRA
3.3 ReLoRA*
-
Sparse Spectral Training
4.1 Preliminaries and 4.2 Gradient Update of U, VT with Σ
4.3 Why SVD Initialization is Important
4.4 SST Balances Exploitation and Exploration
4.5 Memory-Efficient Implementation for SST and 4.6 Sparsity of SST
-
Experiments
5.1 Machine Translation
5.2 Natural Language Generation
5.3 Hyperbolic Graph Neural Networks
-
Conclusion and Discussion
-
Broader Impacts and References
Supplementary Information
A. Algorithm of Sparse Spectral Training
B. Proof of Gradient of Sparse Spectral Layer
C. Proof of Decomposition of Gradient of Weight
D. Proof of Advantage of Enhanced Gradient over Default Gradient
E. Proof of Zero Distortion with SVD Initialization
F. Experiment Details
G. Singular Value Pruning
H. Evaluating SST and GaLore: Complementary Approaches to Memory Efficiency
I. Ablation Study
5.2 Natural Language Generation
We utilize the OPT [9] architecture as the baseline for our language generation experiments. All models are pre-trained on OpenWebText [39], an open-source reproduction of OpenAI’s WebText. To facilitate fair comparisons across different OPT model sizes, we standardize the total training tokens for all models at 19.7 billion. A consistent rank (r = 64) is applied for all low-rank methods.
\ Table 3 displays the validation perplexity results on the OpenWebText dataset across different sizes of OPT models. The results indicate that SST not only achieves lower perplexity scores compared to LoRA and ReLoRA* but also approximates the performance of full-rank training, with significantly fewer trainable parameters.
\ 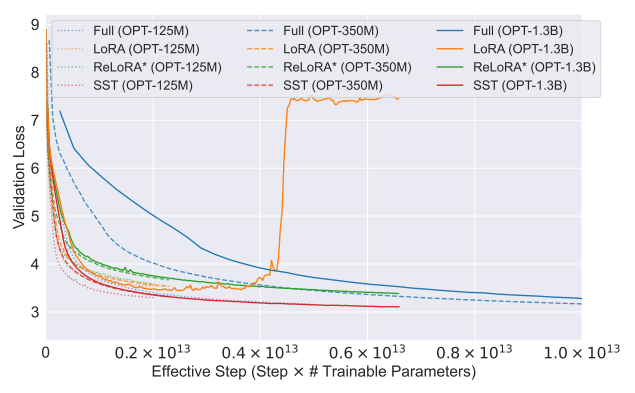
\ Figure 2 illustrates a comparison of effective steps among various training methods. The effective step metric, which considers both the number of trainable parameters and the number of training steps, demonstrates that SST offers a more efficient training approach compared to the full-rank method.
\ Each pretrained model undergoes zero-shot evaluations on all 16 NLP tasks used in OPT article [9], including ARC Easy and Challenge [40], HellaSwag [41], OpenBookQA [42], PIQA [43], StoryCloze [44], SuperGLUE [45], WinoGrad [46], and WinoGrande [47]. Evaluations are conducted using the LM Evaluation Harness framework [48]. Except for the ReCoRD task, which uses F1 score, all other tasks are evaluated using accuracy.
\ Table 4 details the zero-shot evaluation results across the 16 NLP tasks. SST consistently performs comparably or better than other low-rank methods and shows competitive performance against the full-rank models.
\ We further conduct an analysis experiment on inference by doing post-training singular value pruning on SST model (see appendix G).
\
5.3 Hyperbolic Graph Neural Networks
Hyperbolic Graph Neural Networks (HGNNs) [11, 12] capitalize on the expansive and hierarchical nature of hyperbolic space to efficiently manage and analyze graph-structured data. This geometric space is particularly suitable for graphs due to its ability to closely mimic the underlying data structures with minimal distortion, offering a substantial improvement over traditional Euclidean methods.
\ \ 
\ \ We evaluated the effectiveness of SST on HyboNet [12] version HGNN in node classification and link prediction across four distinct datasets: Airport [11], Cora [49], Disease [50], and PubMed [51]. Each experiment was conducted with three random seeds.
\ \ ![Table 4: Zero-shot evaluations on the same 16 NLP tasks featured in the OPT article [9]. Except for the ReCoRD task, which uses F1 score, all other tasks are evaluated using accuracy, with values presented as percentages. Mean scores in bold represent superior performance among the low-rank methods. Additionally, we include the win percentage (counting ties) for each low-rank method compared to the full-rank training.](https://cdn.hackernoon.com/images/fWZa4tUiBGemnqQfBGgCPf9594N2-62132fm.png)
\ \ \ 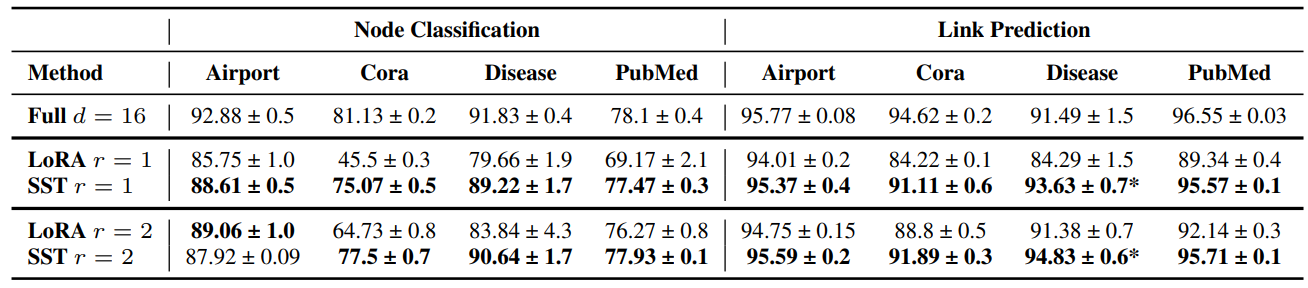
\ \ The results, detailed in Table 5, demonstrate strong performance in both node classification and link prediction tasks. SST not only shows comparable performance to full-rank training (exceeding it in the Disease link prediction task) but also significantly outperforms LoRA at equivalent ranks. Notably, SST’s advantage over LoRA is larger on r = 1 than r = 2, likely due to SST’s sampling strategy being particularly effective in sparser scenarios.
:::info Authors:
(1) Jialin Zhao, Center for Complex Network Intelligence (CCNI), Tsinghua Laboratory of Brain and Intelligence (THBI) and Department of Computer Science;
(2) Yingtao Zhang, Center for Complex Network Intelligence (CCNI), Tsinghua Laboratory of Brain and Intelligence (THBI) and Department of Computer Science;
(3) Xinghang Li, Department of Computer Science;
(4) Huaping Liu, Department of Computer Science;
(5) Carlo Vittorio Cannistraci, Center for Complex Network Intelligence (CCNI), Tsinghua Laboratory of Brain and Intelligence (THBI), Department of Computer Science, and Department of Biomedical Engineering Tsinghua University, Beijing, China.
:::
:::info This paper is available on arxiv under CC by 4.0 Deed (Attribution 4.0 International) license.
:::
\
You May Also Like

REX Shares’ Solana staking ETF sees $10M inflows, AUM tops $289M for first time


Interview | Big tech is training AI on junk data: Intuition
