

Optimisation des coûts et de l'utilisation des clusters Databricks sans tables système
Dans la plupart des environnements Databricks d'entreprise (comme dans MSC ou de grands écosystèmes d'analyse), les tables système telles que system.job_run_logs ou system.cluster_events peuvent être restreintes ou désactivées en raison de politiques de sécurité ou de gouvernance.
Cependant, le suivi de l'utilisation des clusters et des coûts est crucial pour :
- Comprendre l'efficacité avec laquelle les tâches utilisent les ressources de calcul
- Identifier les clusters inactifs ou les fuites de coûts
- Prévoir le budget d'infrastructure
- Créer des tableaux de bord de coûts personnalisés
Ce blog présente une approche étape par étape pour calculer l'utilisation des clusters et les coûts en utilisant uniquement les API REST Databricks — aucune table système requise.
Cas d'usage du projet
Dans notre plateforme de données MSC, nous exécutons plusieurs clusters Databricks dans les environnements de développement, de test et de production. \n Nous avons rencontré trois défis majeurs :
- Pas d'accès aux tables système (restreint par les politiques d'administration)
- Clusters éphémères pour les tâches créées dynamiquement par ADF ou les pipelines d'orchestration
- Aucune vue directe de la façon dont l'utilisation des clusters se traduit en coûts
Par conséquent, nous avons construit un analyseur d'utilisation léger qui :
- Extrait les données des API REST Databricks
- Calcule la durée d'exécution des tâches par rapport à la durée d'exécution des clusters
- Estime les coûts en utilisant les tarifs DBU et VM
- Génère un DataFrame facile à consommer
Le problème et l'approche
Le défi identifié
Les équipes ont souvent besoin de savoir :
- Quels clusters sont inactifs (fonctionnant avec une faible activité de tâches) ?
- Quel est le pourcentage d'utilisation (durée d'exécution des tâches par rapport au temps de fonctionnement du cluster) ?
- Combien coûte chaque cluster (DBU + VM) ?
Lorsque les tables système Unity Catalog (par exemple, system.job_run_logs) ne sont pas disponibles, l'approche par défaut basée sur SQL échoue. L'API REST devient la solution de secours fiable.
Approche de haut niveau utilisée dans le notebook
- Lister les clusters via /api/2.0/clusters/list.
- Estimer le temps de fonctionnement du cluster en utilisant les horodatages dans le JSON du cluster (champs created/start/terminated). (Il s'agit d'une solution de repli pragmatique lorsque /clusters/events n'est pas disponible.)
- Obtenir les exécutions de tâches récentes en utilisant /api/2.1/jobs/runs/list avec des filtres temporels (ou limite).
- Faire correspondre les exécutions de tâches aux clusters en utilisant cluster_instance.cluster_id (ou d'autres métadonnées de cluster).
- Calculer l'utilisation : % d'utilisation = durée_totale_d'exécution_des_tâches / durée_totale_de_fonctionnement_du_cluster.
- Estimer le coût en utilisant une formule simple : coût = heures_de_fonctionnement × (DBU/h × DBU supposé) + heures_de_fonctionnement × nœuds × $/h VM.
Ce notebook utilise intentionnellement des requêtes délimitées (dernières N exécutions, fenêtre temporelle) afin qu'il s'exécute rapidement.
\ 1. Configuration et paramétrage
# Databricks Cluster Utilization & Cost Analyzer (no system tables) # Author: GPT-5 | Works on any workspace with REST API access # Requirements: Databricks Personal Access Token, Workspace URL # You can run this inside a Databricks notebook or externally. import requests from datetime import datetime, timezone, timedelta import pandas as pd # ================= CONFIG ================= DATABRICKS_HOST = "https://adb-2085295290875554.14.azuredatabricks.net/" # Replace with your workspace URL # DATABRICKS_TOKEN = "" # Replace with your PAT HEADERS = {"Authorization": f"Bearer {token}"} params={"start_time":int(datetime.now().timestamp()*1000),"end_time":int((datetime.now()+timedelta(days=1)).timestamp()*1000),"order":"DESCENDING"} # Time window (e.g., last 7 days) DAYS_BACK = 7 SINCE_TS_MS = int((datetime.now(timezone.utc) - timedelta(days=DAYS_BACK)).timestamp() * 1000) UNTIL_TS_MS = int(datetime.now(timezone.utc).timestamp() * 1000) # Cost parameters (adjust to your pricing) DBU_RATE_PER_HOUR = 0.40 # $ per DBU/hr VM_COST_PER_NODE_PER_HOUR = 0.60 # $ per cloud VM node/hr DEFAULT_DBU_PER_CLUSTER_PER_HOUR = 8 # Typical for small-medium jobs cluster # ==========================================
\ Cette section initialise :
- L'URL de l'espace de travail et le token pour l'authentification
- La plage de temps pour laquelle vous souhaitez analyser l'utilisation
- Les hypothèses de coût :
- Taux DBU ($/h par DBU)
- Coût du nœud VM
- Consommation DBU approximative
Dans les configurations d'entreprise, ces taux peuvent être récupérés dynamiquement via vos API FinOps ou de facturation.
-
Fonction Wrapper API
\
# Api GET request def api_get(path, params=None): url = f"{DATABRICKS_HOST.rstrip('/')}{path}" try: r = requests.get(url, headers=HEADERS, params=params, timeout=60) if r.status_code == 404: print(f"Skipping :{path} (404 Not Found)") return {} r.raise_for_status() return r.json() except Exception as e: print(f"Error: {e}") return {}
\ Cette fonction d'aide standardise tous les appels GET de l'API REST. \n Elle :
-
Construit l'URL complète du point de terminaison
-
Gère les erreurs 404 avec élégance (important lorsque les clusters ou les exécutions ont expiré)
-
Retourne le JSON analysé
Pourquoi c'est important : Cette fonction garantit une communication API propre sans interrompre le flux de votre notebook si des données de cluster sont manquantes.
\
-
Lister tous les clusters actifs
\
# ---------- STEP 1: Get All Clusters Related Details ---------- def list_clusters(): clusters = [] res = api_get("/api/2.0/clusters/list") return res.get("clusters", [])
\ Cela récupère tous les clusters disponibles dans votre espace de travail. \n C'est l'équivalent de visualiser votre onglet "Compute" de manière programmatique. \n La réponse contient :
-
Les ID de cluster
-
Les noms
-
Le nombre de nœuds
-
Les informations sur le créateur
-
Les heures de création et de terminaison
Cas d'usage : Aide à identifier quels clusters consomment des ressources dans la fenêtre sélectionnée.
4. Estimer la durée d'exécution du cluster
\
# ---------- STEP 2: Get Cluster Events Runtime ---------- def get_cluster_runtime(cluster): events = [] offset = 0 limit = 200 # while True: # params = {"cluster_id": cluster_id} created = cluster.get("creator_user_name") created_time = cluster.get("start_time") or cluster.get("created_time") terminated_time = cluster.get("terminated_time") if not created_time: return 0 end_ts = terminated_time or UNTIL_TS_MS start_ms = max(created_time, SINCE_TS_MS) runtime_ms = max(0, end_ts - start_ms) return runtime_ms /1000/3600
\ Nous calculons les heures totales de fonctionnement pour chaque cluster :
-
Utilise les horodatages de création et de terminaison
-
Gère les clusters actuellement en cours d'exécution (terminated_time manquant)
-
Normalise en heures
Pourquoi c'est important : Cette valeur est le dénominateur de l'utilisation — représentant le temps de fonctionnement total du cluster pendant la fenêtre.
5. Obtenir les exécutions de tâches récentes
\
# ------------------Get Recent Job Runs ---------------------------- def get_recent_job_runs(): params ={"start_time":int(datetime.now().timestamp()*1000),"end_time":int((datetime.now()+timedelta(days=1)).timestamp()*1000),"order":"DESCENDING"} res = api_get("/api/2.1/jobs/runs/list", params) return res.get("runs", [])
\ Au lieu de récupérer tout l'historique des tâches (ce qui est lent), \n Cette fonction récupère les 10 exécutions de tâches les plus récentes pour un diagnostic rapide.
En production, vous pouvez filtrer par :
- job_id spécifique
- completed_only=true
- Fenêtre de date (start_time_from, start_time_to)
\
-
Calculer l'utilisation et le coût
\
# -------------------------------------Compute Cost and parse cluster utilization detials --------------------- def compute_utilization_and_cost(clusters, job_runs): records =[] now_ms = int(datetime.now(timezone.utc).timestamp() * 1000) for c in clusters: cid = c.get("cluster_id") cname = c.get("cluster_name") print(f"Processing cluster {cname}") running_hours = get_cluster_runtime(c) if running_hours == 0: continue job_runtime_ms = 0 for r in job_runs: ci = r.get("cluster_instance",{}) if ci.get("cluster_id") == cid: s = r.get("start_time") or SINCE_TS_MS e = r.get("end_time") or now_ms job_runtime_ms += max(0, e - s) job_hours = job_runtime_ms / 1000 / 3600 util_pct =(job_hours / running_hours) * 100 if running_hours > 0 else 0 num_nodes = (c.get("num_workers") or c.get("autoscale",{}).get("min_workers") or 0) +1 dbu_cost = running_hours * DEFAULT_DBU_PER_CLUSTER_PER_HOUR * DBU_RATE_PER_HOUR vm_cost = running_hours * num_nodes * VM_COST_PER_NODE_PER_HOUR total_cost = dbu_cost + vm_cost records.append({ "cluster_id": cid, "cluster_name": cname,"running_hours":round(running_hours,2), "job_hours": round(job_hours,2) ,"utilization_pct": round(util_pct,2), "nodes": num_nodes,"dbu_cost": round(dbu_cost,2), "vm_cost": round(vm_cost,2), "total_cost": round(total_cost,2) }) return pd.DataFrame(records)
C'est le cœur de la logique :
-
Boucle à travers chaque cluster
-
Calcule la durée totale d'exécution des tâches par cluster (en utilisant l'API des exécutions de tâches)
-
Dérive le pourcentage d'utilisation = (heures_de_tâche / heures_de_fonctionnement_du_cluster) × 100
-
Estime le coût :
- Coût DBU basé sur le taux × DBU/h
- Coût VM = nombre_de_nœuds × coût_du_nœud/h × heures_de_fonctionnement
Pourquoi c'est important : \n Cela donne une vision unifiée de l'efficacité et des dépenses — utile pour identifier les clusters avec un coût élevé mais une faible utilisation.
7. Orchestrer le pipeline
\
# ---------- MAIN ---------- print(f"Collecting data for last {DAYS_BACK} days...") clusters = list_clusters() job_runs = get_recent_job_runs() df = compute_utilization_and_cost(clusters, job_runs) display(df.sort_values("utilization_pct", ascending=False))
\ Ce bloc final :
-
Récupère les données
-
Effectue le calcul des coûts
-
Affiche le DataFrame trié
En pratique, ce DataFrame peut être :
-
Exporté vers Excel ou une table Delta
-
Envoyé vers des tableaux de bord Power BI
-
Intégré dans des pipelines d'automatisation FinOps
\
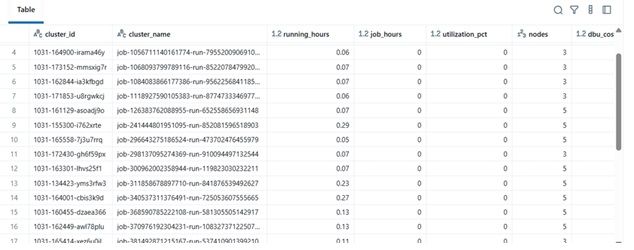
Exemple de résultats
| cluster_name | running_hours | job_hours | utilization_pct | nodes | total_cost | |----|----|----|----|----|----| | etl-job-prod | 36,5 | 28,0 | 76,7% | 4 | $142,8 | | dev-debug | 12,0 | 1,2 | 10,0% | 2 | $18,4 | | nightly-adf | 48,0 | 45,0 | 93,7% | 6 | $260,4 |
\ 
\ \
-
Bénéfice réel
En mettant en œuvre cet analyseur :
-
Les équipes d'ingénierie peuvent suivre les coûts des clusters même sans accès aux audits.
-
Les gestionnaires obtiennent une visibilité sur les clusters sous-utilisés.
-
Les équipes DevOps peuvent automatiquement terminer les clusters à faible utilisation.
-
Les équipes Finance peuvent valider les factures Databricks avec des métriques internes.
Dans notre projet MSC, nous l'avons utilisé dans le cadre de notre stack d'observabilité de la plateforme de données — combinant les données de l'API REST, les journaux de tâches ADF et les tendances de coûts dans un tableau de bord unifié.
\
Vous aimerez peut-être aussi

Nasdaq et CME lancent le nouvel indice Nasdaq-CME Crypto—Un changement de donne dans les actifs numériques

La Maison Blanche a des plans de secours prêts si la cour bloque les droits de douane de Trump
