

Matting Robusto Guiado por Máscara: Gestión de Entradas Ruidosas y Versatilidad de Objetos
Tabla de Enlaces
Resumen y 1. Introducción
-
Trabajos Relacionados
-
MaGGIe
3.1. Matting de Instancia Guiado por Máscara Eficiente
3.2. Consistencia Temporal Feature-Matte
-
Conjuntos de Datos de Matting de Instancia
4.1. Matting de Instancia de Imagen y 4.2. Matting de Instancia de Video
-
Experimentos
5.1. Pre-entrenamiento con datos de imagen
5.2. Entrenamiento con datos de video
-
Discusión y Referencias
\ Material Suplementario
-
Detalles de arquitectura
-
Matting de imagen
8.1. Generación y preparación del conjunto de datos
8.2. Detalles de entrenamiento
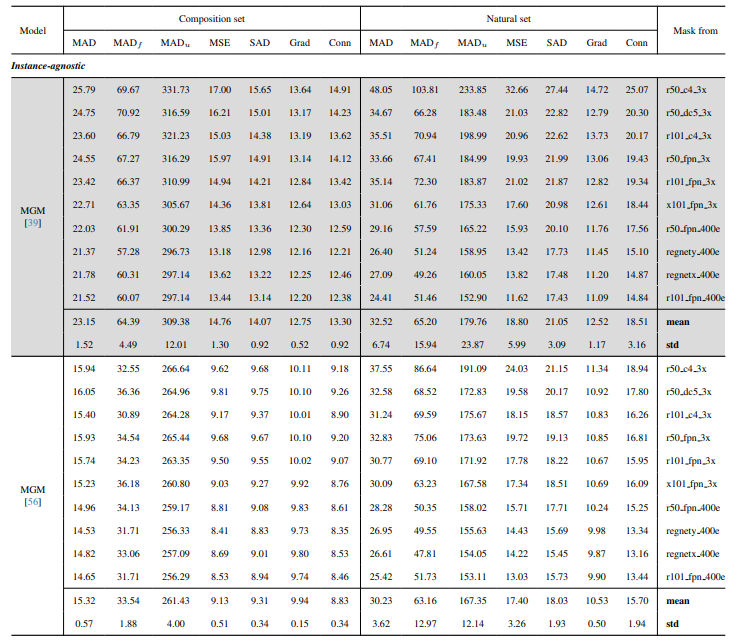
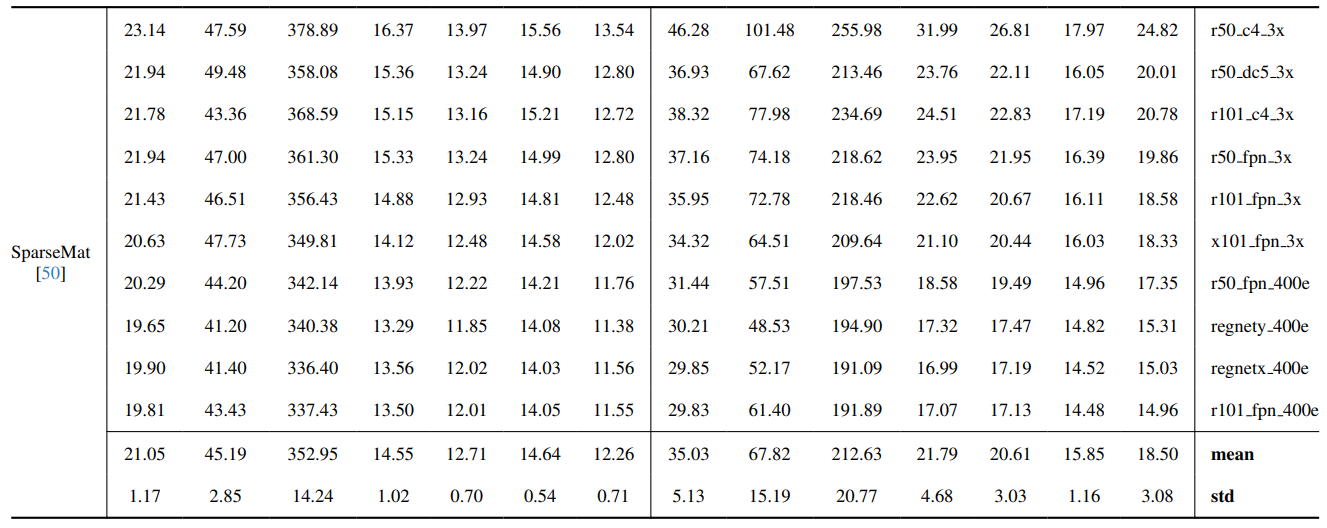
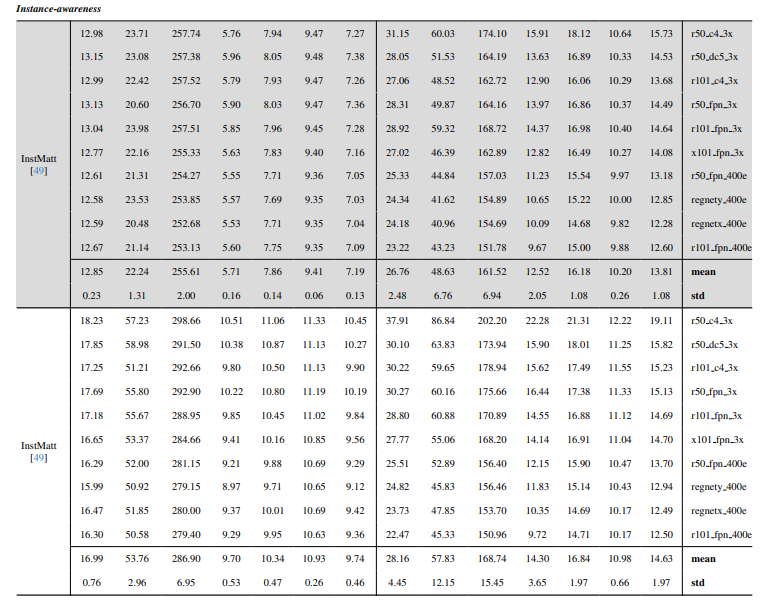
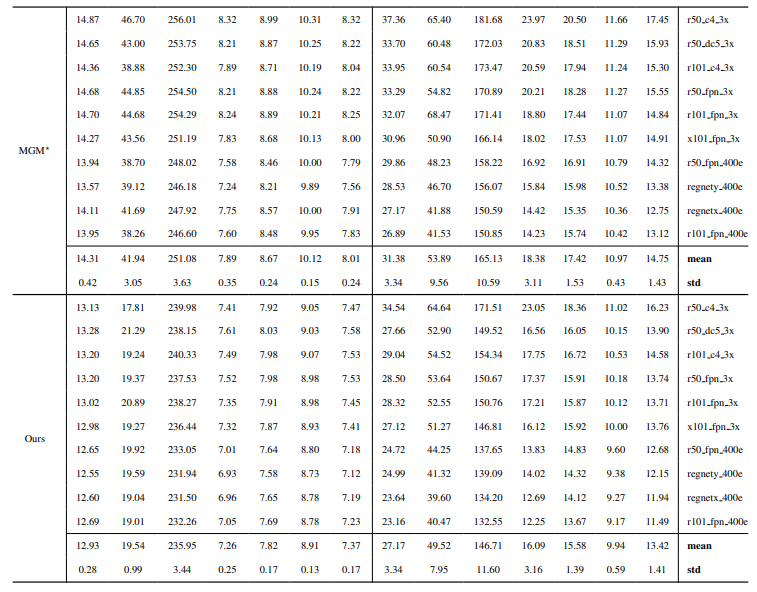
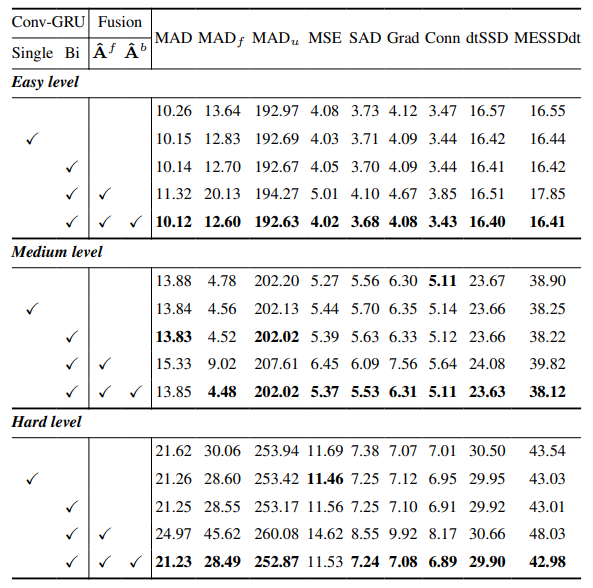
8.3. Detalles cuantitativos
8.4. Más resultados cualitativos en imágenes naturales
-
Matting de video
9.1. Generación del conjunto de datos
9.2. Detalles de entrenamiento
9.3. Detalles cuantitativos
9.4. Más resultados cualitativos
8.4. Más resultados cualitativos en imágenes naturales
La Fig. 13 muestra el rendimiento de nuestro modelo en escenarios desafiantes, particularmente en la renderización precisa de regiones de cabello. Nuestro framework supera consistentemente a MGM⋆ en la preservación de detalles, especialmente en interacciones complejas de instancias. En comparación con InstMatt, nuestro modelo exhibe una separación de instancias y precisión de detalles superior en regiones ambiguas.
\ La Fig. 14 y la Fig. 15 ilustran el rendimiento de nuestro modelo y trabajos anteriores en casos extremos que involucran múltiples instancias. Mientras que MGM⋆ tiene dificultades con ruido y precisión en escenarios de instancias densas, nuestro modelo mantiene alta precisión. InstMatt, sin datos de entrenamiento adicionales, muestra limitaciones en estos entornos complejos.
\ La robustez de nuestro enfoque guiado por máscara se demuestra además en la Fig. 16. Aquí, destacamos los desafíos que enfrentan las variantes de MGM y SparseMat al predecir partes faltantes en las entradas de máscara, que nuestro modelo aborda. Sin embargo, es importante notar que nuestro modelo no está diseñado como una red de segmentación de instancias humanas. Como se muestra en la Fig. 17, nuestro framework se adhiere a la guía de entrada, asegurando una predicción precisa de alpha matte incluso con múltiples instancias en la misma máscara.
\ Por último, la Fig. 12 y la Fig. 11 enfatizan las capacidades de generalización de nuestro modelo. El modelo extrae con precisión tanto sujetos humanos como otros objetos de los fondos, mostrando su versatilidad en diversos escenarios y tipos de objetos.
\ Todos los ejemplos son imágenes de Internet sin ground-truth y la máscara de r101fpn400e se utiliza como guía.
\ 
\ 
\ 
\ 
\ 
\ 
\ 
\ 
\ 
\ 
\
:::info Autores:
(1) Chuong Huynh, University of Maryland, College Park (chuonghm@cs.umd.edu);
(2) Seoung Wug Oh, Adobe Research (seoh,jolee@adobe.com);
(3) Abhinav Shrivastava, University of Maryland, College Park (abhinav@cs.umd.edu);
(4) Joon-Young Lee, Adobe Research (jolee@adobe.com).
:::
:::info Este artículo está disponible en arxiv bajo licencia CC by 4.0 Deed (Atribución 4.0 Internacional).
:::
\


También te puede interesar

La construcción de Masjid Warisan frente a la torre TRX seguirá adelante, dice el ministro que es un plan de larga data

Shopify (SHOP) Stock: la plataforma se prepara para prohibir todos los productos de vapeo esta semana

Máxima caída de Bitcoin al 49% señala un ciclo más moderado que los crashes anteriores



